[MLOps] Andrew Ng: Model-centric AI에서 Data-centric AI로
MLOps를 통해 모델 중심 AI에서 데이터 중심 AI로 가야한다는 Andrew Ng 교수의 최근 강연 A Chat with Andrew on MLOps: From Model-centric to Data-centric AI(2021–03–25)를 회사 동료분 추천으로 보게 되었는데, 시사점이 좋아서 정리해보았다.
Ng교수에 따르면, Data-centric AI라는 주제에 대해서 1년 이상 준비해왔기도 하고 동료들과도 많이 고민해온 주제인데, 공식 발표는 처음이라고 한다. 그래서 이 주제에 대해서 많이 ‘spread the words’를 해주고 사람들이 더 data-centric으로 일할 수 있었으면 좋겠다는 이야기를 하기도 해서, 주요 내용 위주로 정리해보고자 한다.
AI system = Code(Model, Algorithm) + Data
AI 시스템은 코드(모델, 알고리즘)과 데이터로 구성되어있다.
먼저 결함이 있는 철판을 찾는 문제를 예시로 한번 생각해보자.
기존 시스템은 76.2%의 accuracy로 결함을 찾아낼 수 있고, 목표로는 90.0%의 accuracy를 갖는 모델을 만들고자 한다.
아래 문제를 풀기 위해 code와 data 중 어떤 것을 개선하는 것이 좋을까?

실제 프로젝트를 수행한 결과가 아래 표에 나와 있다.
먼저 model-centric한 방식으로 개선에 힘써봤지만 개선 비율은 0%로, 전혀 개선하지 못했다. 반면에 data-centric한 방식으로 data를 개선했더니 모델의 성능을 무려 16.9% 더 개선할 수 있었다.
이외에 다른 문제들도, 일반적으로 data-centric한 접근이 조금이라도 더 나은 성능을 보였다.

농담처럼 data science 업무의 80%는 data cleansing이 차지한다고 이야기하기도 하는데, 농담이 아니라 실제로 머신러닝 엔지니어링의 core part는 high quality의 data를 preparing하는 것이다.
그런데 AI 연구자료의 Abstract를 훑어보면, 99%의 리서치가 알고리즘과 모델에 관한 것이고, 실제 80%의 업무 분량을 차지하는 data preparation은 1% 정도의 분량밖에 보이지 않는다.
ML 업무의 80%의 분량을 차지하는 data에 더 관심을 갖고, 시스템적으로 이를 개선하기 위한 노력이 필요하다.

Making data quality systematic: MLOps
그럼 Data의 quality 관리는 어떻게 되어야할까?
labeling을 예시로 들면,
- 각각의 labeler가 sample image를 레이블링한다.
- 같은 이미지를 각각의 labeler가 레이블링한 일관성을 측정한다.
- 각각의 labeler가 다르게 판단한 classe들이 일관성 있게 판단될 수 있을때까지 instruction을 수정한다.

Making it systematic: MLOps
Model-centric view와 Data-centric view의 차이
- Model-centric view
- 수집할 수 있는 최대한의 데이터를 모으고, 데이터의 노이즈에 대응할 수 있는 모델을 개발한다.
- 데이터는 fix된 상태에서 code/model을 반복적으로 개선(iteratively improve) 한다. - Data-centric view
- 데이터의 일관성이 다른 무엇보다 중요하다.
데이터의 퀄리티를 개선할 수 있는 tool들을 사용한다; 그 결과 다양한 모델이 잘 동작할 수 있도록 돕는다.
- code는 fix된 상태에서 data를 반복적으로 개선한다.
Small Data and Label Consistency
현실속의 많은 ML 모델의 트레이닝 데이터셋 사이즈는 생각보다 크지 않은 경우가 많다. 수억, 수만개의 문제보다 1만개 이하의 작은 데이터셋을 가진 문제들이 더 많다. (과학적 통계는 아니지만) Kaggle의 데이터셋만 예시로 들어보아도, 1K~10K개 내외의 작은 데이터셋 사이즈가 가장 많다.
이렇게 작은 데이터셋일 수록, label의 일관성이 더욱 중요해진다. 아래 그림을 예시로 보자.
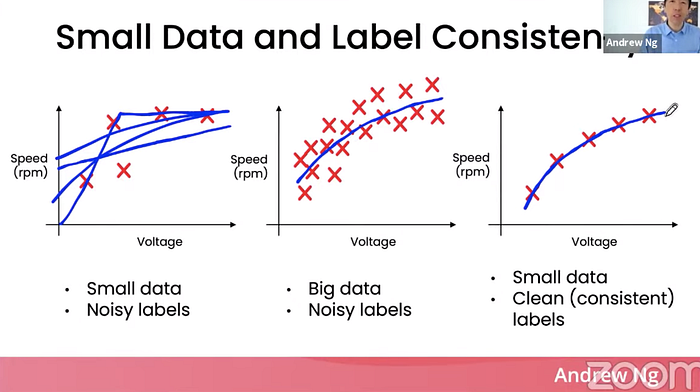
- 위 그림의 가장 좌측 그래프는 noisy label을 가진 small data로 학습한 모델
- 가운데는 noisy label을 가진 big data로,
- 우측은 clean한 small data로 학습한 모델이다.
빅데이터의 경우는 noisy label이 있어도 어느 정도 극복이 가능하다. 하지만 small data일수록 noisy 데이터의 여부가 모델 성능에 훨씬 더 큰 영향을 미친다.
Theory: Clean vs. noisy data
500개의 샘플 중 12%의 샘플이 noisy 한 경우(incorrectly or inconsistently labeled)를 가정하자.
이때 아래 두가지의 방법이 동일한 효과를 가진다.
- noise를 클린업 한다.
- 또다른 500개의 샘플을 수집한다.(트레이닝셋을 두배로 만든다)
500개중 12%의 샘플이 noisy하다면 약 60개의 샘플인데, 이 경우 noise를 클린업 하는게 훨씬 더 효율적일 것이다. 특히 10,000개 이하의 샘플 문제를 개선하는데 data centric view가 큰 기회를 제공할 수 있다.
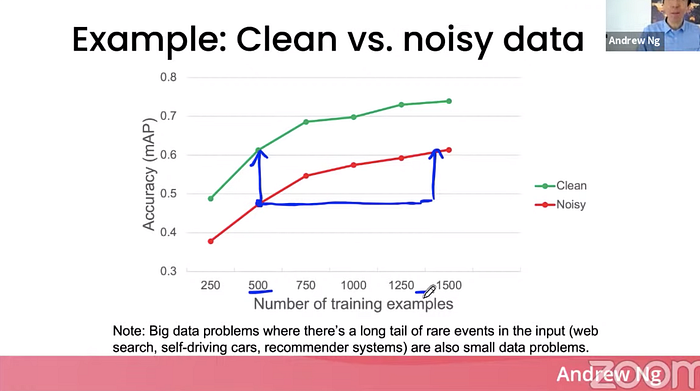
전체 샘플 수가 작은 문제들만 small data problem이 아니다.
대표적인 web search 데이터를 생각해보자. 엄청나게 많은 데이터를 가지고 있을 것이 분명하지만, 이런 빅데이터 문제 중 롱테일의 희소한 입력값을 가진 문제들(web search, self-driving cars, 추천 시스템) 문제 또한 small data problem으로 볼 수 있다.
Train Model: Speech Recognition
data centric으로 문제를 풀었던 사례를 하나 보자.
speech recognition 문제에서, 자동차 소음 때문에 알고리즘의 성능이 안좋은 경우가 있었다. 한참 모델을 개선하다가, 모델의 개선을 멈추고, 팀원들이 data 개선에 더 집중하기로 했다. 이때부터 눈에 띄는 성능의 개선이 나타나기 시작했다.
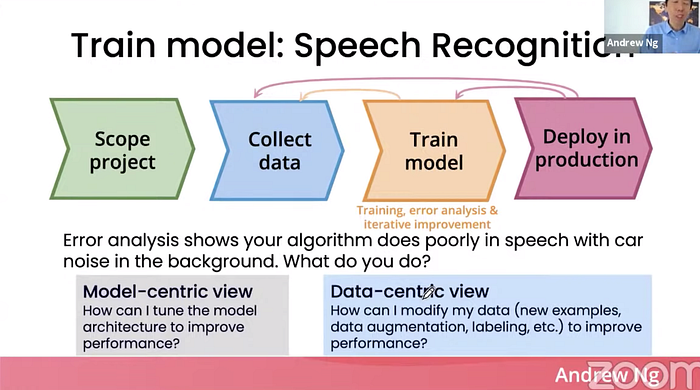
모델 트레이닝:
반복적으로 데이터를 개선하는 과정을 시스템화 하자.
- 모델을 학습
- 알고리즘이 성능이 좋지 않은 타입에 대해서 Error analysis를 수행(e.g., speech with car noise)
- x입력값에 대한 변경 : 데이터를 더 수집하거나, 데이터의 정제
y레이블에 대한 변경 : 더 일관된 레이블링 정의
Deploy:
배포된 모델의 성능을 모니터링하고 모델의 지속적 개선을 위해 새로운 데이터를 주입하자.
- 환경과 데이터가 변하는 것(concept drift/data drift)에 대해서 시스템적으로 체크해야 한다.
- 데이터를 다시 주입해서 모델을 정기적으로 업데이트해야한다
MLOps의 정의
상대적으로 최근 생겨난 단어인 MLOps의 세부적인 정의는 모두가 조금씩 다르게 하고 있지만, MLOps의 큰 정의는 위에서 언급한 모델 개발과 배포를 시스템화하는 것이다.
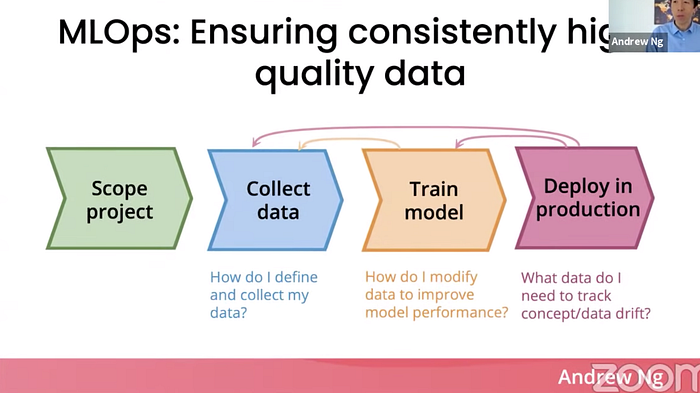
또한 Ng교수가 생각하는 MLOps의 가장 핵심은 ML lifecycle의 전 과정인 Collect data부터 Deploy production까지 high quality의 데이터를 공급할 수 있도록 하는 것이다.

이를 통해 단순 Big data에서 Good data의 활용이 필요하다.
Good data란:
- 일관성 있는 정의(y 레이블의 정의가 분명하다)
- 중요한 케이스에 대한 커버(x입력값에 대한 good coverage)
- 운영 데이터로부터의 빠른 피드백(배포 후 환경의 변화에 대한 감지)
- 적절한 사이즈
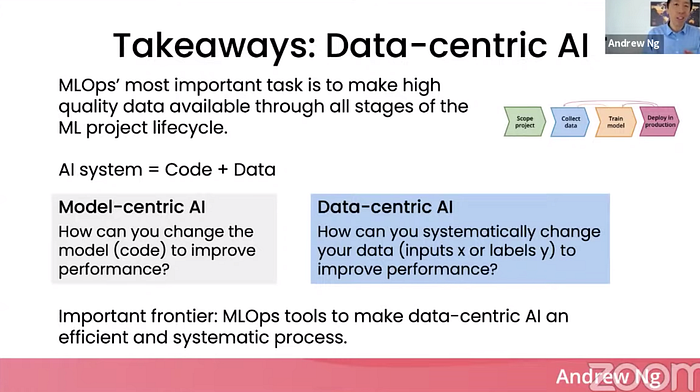
Takeaways: Data-centric AI
주요 시사점
- MLOps의 가장 중요한 태스크는 high quality의 데이터를 모든 ML project lifecycle에 공급하는 것이다.
- Data-centric AI는 모델을 통한 개선보다 데이터를 통한 성능 개선을 위해 노력하는 것이다.
- 효율적, 시스템적으로 data-centric AI를 가능케 해줄 프레임워크, 툴의 활용이 필요하다.
덧
그리고 질답등의 뒷 이야기 플러스.
- Ng: 지금의 git을 이용한 version control이 얼마나 행복한 것인지 code의 version control이 없던 시절을 한번 생각해보자!
- A: “나 코드 수정 다 했어.”
- A-> B 메일로 코드 보냄.
- A: “너가 수정해. 3시간 동안 하고 알려줘. 3시간 뒤에 내가 다시 할거거든.”
3시간 뒤..
- B: “나도 다했어.”
- B->A 메일로 다시 코드 받음
…..이러던 시절을 생각하면 지금의 version control은 얼마나 좋은가?! - 개인적으로 version control 관련해서는, 이전에 금융권에서 IBM의 Clear Case라는 형상관리 툴을 썼던 사람으로서 정말 공감하는 부분이다.
메일로 직접 코드를 보내는 부분만 빼면 저런 식의 대화가 정말 많았다…
‘과장님 DAO 파일 수정 끝나셨으면 check out 좀 풀어주세요~’ 란 요청을 얼마나 많이 했던가…? ㅎㅎ… 누가 패키지 전체라도 check out해놓고 휴가가면 수정 못해.. - Q : data-centric AI와 model-centric AI를 hybrid로 쓰면 안되나?
Ng :물론 가능하다.
그런데 우리가 그동안 model의 개발에 엄청난 리서치 역량을 많이 써왔기 때문에, 사실 모델은 github에서 좋은 모델만 받아와서 적용해도 좋은 성능을 내고, 더 개선하기가 쉽지 않다. 하지만 데이터는 (프로젝트별/비즈니스별로) 개선할 점이 아주 많다.
Reference
Andrew Ng, A Chat with Andrew on MLOps: From Model-centric to Data-centric AI (DeepLearningAI)
