[Apache Spark] 조인(Join), 셔플(Shuffle) 최적화
Spark의 Join은 크게 SQL Optimizer를 활용하는 SQL Join과 DAG Optimizer를 활용하는 low level(RDD)의 Core Spark Join으로 분류할 수 있다. Join의 개념과 효율적 Join 방법에 대해 알아보았다.
SQL Optimizer와 달리 DAG Optimizer는 연산 순서를 재정렬하거나 필터 푸시다운 능력이 없으므로 연산 순서의 고려가 더욱 중요하다.
CORE SPARK JOIN
RDD 형태의 조인.
DataFrame과 DataSet을 통한 Spark coding이 훨씬 보편적이고, 추천되는 방식이기도 한 지금에 와서는, 직접 RDD를 활용해 low level의 API를 사용할 이유는 특별히 목적이 있는 경우를 제외하고는 많지 않을 것이다.
하지만, 스파크의 모든 워크로드는 저수준 기능을 사용하는 기초적인 형태로 컴파일되므로 이 구조를 이해해두는 것이 효율적 활용에 도움이 될 수 있다.
- 일반적으로 JOIN은 동일한 키의 데이터가 동일한 파티션 내에 있어야 하므로 비용이 비싼 작업이다.
RDD의 Known Partitionor 를 갖고 있지 않다면 이를 공유하도록 셔플이 필요하고, 이를 통해 동일한 키의 데이터는 동일한 파티션에 위치하게 된다. - 조인의 비용은 키의 개수와 올바른 파티션으로 위치하기 위해 움직이는 규모에 비례해서 커진다.
Basic RDD Join
def joinScoresWithAddress1( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
val joinedRDD = scoreRDD.join(addressRDD)
joinedRDD.reduceByKey( (x, y) => if(x._1 > y._1) x else y )
}- shuffle join with wide dependency
RDD들이 known partitioner를 갖고 있지 않다면, RDD간 같은 partitioner를 가질 수 있도록 shuffle이 일어난다.
이를 통해 같은 key의 데이터들은 같은 partition에 있을 수 있게 된다.
(wide dependency와 narrow dependency의 차이가 궁금하면 본 글 가장 하단의 [참고]로!)

- shuffle join with narrow dependency
RDD중 하나라도 known partitioner를 갖고 있다면, narrow depency + shuffle join이 일어난다. (partitioner의 동일 여부 관계 없음)

- Colocated Join
RDD간 이미 같은 partitioner를 갖고 있다면 데이터는 executor안에서 재배치만 일어나고, 네트워크간 이동을 피할 수 있다.

- Speeding up with known partitioner join
조인 전에 aggregateByKey, reduceByKey와 같은 작업이 필요한 경우, join 전에 hash partitioner로 파티션을 명시적으로 지정함을 통해 known partitioner를 생성하고, 이를 통해 이후에 따르는 조인 작업 시 shuffle을 방지할 수 있다.
def joinScoresWithAddress3(scoreRDD: RDD[(Long, Double)],
addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, String))]= {
// If addressRDD has a known partitioner we should use that,
// otherwise it has a default hash parttioner, which we can reconstruct by
// getting the number of partitions.
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length)
}
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner,
(x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}조인 형태 선택
- 양쪽 RDD가 중복 키를 갖고 있다면 키 공간을 줄이기 위해 distinct나 combineByKey 연산을 수행하거나 중복 키를 관리할 수 있는 cogroup을 통해 full cross join은 피하는 것이 좋다.
- 키가 양쪽 RDD에 모두 존재하는 것이 아니라면 유실 위험이 있으므로 outer join을 사용하는 것이 더 안전할 수 있다.
- 규모가 큰 데이터의 셔플을 피하기 위해 조인 전에 필터링 등의 방법으로 크기를 미리 감소시키는 것이 더 좋을 수도 있다.
- 조인은 일상적으로 쓰이는 스파크 연산 중 가장 비싼 축에 속하므로 조인을 수행하기 전에 데이터를 최대한 줄여놓는 것은 그만한 가치가 있다.
실행 계획 선택
- 데이터 조인을 위해서는 각 키와 연결된 데이터가 같은 파티션 안에 있어야 한다.
- 스파크의 기본 조인은 shuffled hash join이다 : 양쪽 RDD의 같은 hash값의 키들이 같은 파티션에 위치하도록 한다.
이 방법은 항상 동작하기는 하지만 기본적으로 셔플을 필요로 하므로 많은 비용이 들어갈 수 있다. 셔플을 피하는 방법은 없을까?
셔플을 피하는 방법
- known partitioner : 양쪽 RDD가 명시적인 파티셔너를 가진다.
- broadcast hash join : 한쪽 데이터세트가 메모리에 들어갈 만큼 작다면, broadcast hash join을 할 수 있다. 작은쪽 RDD를 모든 워커 노드에 넣어 놓는다. 이를 통해 큰쪽의 RDD와 맵사이드 연결이 이루어질 수 있다.
- 스파크 SQL은 알아서 broadcast join을 할만큼 똑똑하다.(항상 보장되지는 않지만)
스파크 SQL에서는 spark.sql.autoBroadcastJoinThreshold와 spark.sql.broadcastTimeout으로 broadcast setting을 제어할 수 있다.
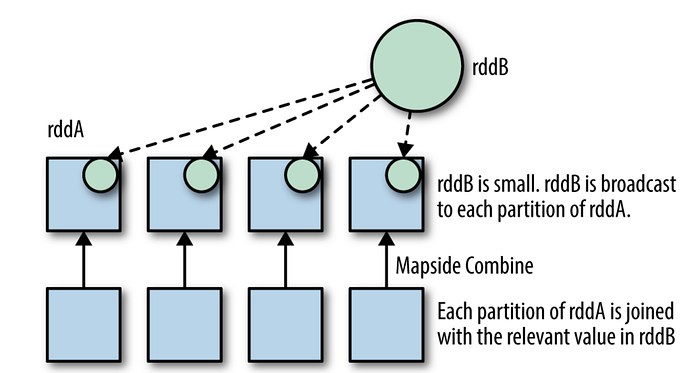
- Partial manual broadcast hash join
소수의 키에 데이터가 크게 몰려 있어서 메모리에 올릴 수 없는 경우, 몰려 있는 키만 빼고 일반 키들만으로 broadcast join을 하는 방법도 고려해볼 수 있다. 각각 키별로 필터링하여 broadcast join과 일반적인 join을 나눠서 수행하고 union으로 합치는 방법이다. 이 방법은 다루기 힘든 심하게 skewed된 데이터를 다룰 때 고려해볼 수 있을 것이다.
SPARK SQL JOIN
Push down이나 연산 순서 재정렬 등, 웬만한 건 SPARK SQL Optimizer가 알아서 해줄 것이다. (얼마나 좋은 세상인가?)
그대신 사용자의 의도에 따라 튜닝할 수 있는 자유도는 좀 제한될 수 있다.
- 지원하는 join 형태 : “inner,” “left_outer” (aliased as “outer”), “left_anti,” “right_outer,” “full_outer,” and “left_semi.”
// Inner join implicit
df1.join(df2, df1("name") === df2("name"))
// Inner join explicit
df1.join(df2, df1("name") === df2("name"), "inner")
// Left outer join explicit
df1.join(df2, df1("name") === df2("name"), "left_outer")
- broadcast hash join
queryExecution.executedPlan을 통해서 수행되는 조인의 타입을 확인할 수 있다. Core Spark에서처럼 작은 테이블을 broadcast hash join할 수 있다. (e.g.,df1.join(broadcast(df2), "key"))
spark sql의 자동 결정을 위한 설정은 위에서 언급했듯, spark.sql.conf.autoBroadcastJoinThreshold와 spark.sql.broadcastTimeout으로 제어할 수 있다.
[참고]
wide dependency와 narrow dependency의 차이
(넓은 종속성과 좁은 종속성)
- Wide dependency: 부모 RDD 파티션이 다수의 자식 RDD 파티션으로 사용되는 경우. 즉, Shuffle이 발생하는 경우. (groudByKey, ReduceByKey, sortByKey 등)
- Narrow Dependency: 부모 RDD의 파티션이 최대 1개의 자식 RDD 파티션에 사용되는 경우. (Map, filter, union, 등)

Reference
Holden Karau, High Performance Spark, JPub, pp.81~93, 2017
